54 | 存储虚拟化(下):如何建立自己保管的单独档案库?





讲述:刘超
时长16:25大小15.05M
上一节,我们讲了 qemu 启动过程中的存储虚拟化。好了,现在 qemu 启动了,硬盘设备文件已经打开了。那如果我们要往虚拟机的一个进程写入一个文件,该怎么做呢?最终这个文件又是如何落到宿主机上的硬盘文件的呢?这一节,我们一起来看一看。
前端设备驱动 virtio_blk
虚拟机里面的进程写入一个文件,当然要通过文件系统。整个过程和咱们在文件系统那一节讲的过程没有区别。只是到了设备驱动层,我们看到的就不是普通的硬盘驱动了,而是 virtio 的驱动。
virtio 的驱动程序代码在 Linux 操作系统的源代码里面,文件名叫 drivers/block/virtio_blk.c。
前面我们介绍过设备驱动程序,从这里的代码中,我们能看到非常熟悉的结构。它会创建一个 workqueue,注册一个块设备,并获得一个主设备号,然后注册一个驱动函数 virtio_blk。
当一个设备驱动作为一个内核模块被初始化的时候,probe 函数会被调用,因而我们来看一下 virtblk_probe。
在 virtblk_probe 中,我们首先看到的是 struct request_queue,这是每一个块设备都有的一个队列。还记得吗?它有两个函数,一个是 make_request_fn 函数,用于生成 request;另一个是 request_fn 函数,用于处理 request。
这个 request_queue 的初始化过程在 blk_mq_init_queue 中。它会调用 blk_mq_init_allocated_queue->blk_queue_make_request。在这里面,我们可以将 make_request_fn 函数设置为 blk_mq_make_request,也就是说,一旦上层有写入请求,我们就通过 blk_mq_make_request 这个函数,将请求放入 request_queue 队列中。
另外,在 virtblk_probe 中,我们会初始化一个 gendisk。前面我们也讲了,每一个块设备都有这样一个结构。
在 virtblk_probe 中,还有一件重要的事情就是,init_vq 会来初始化 virtqueue。
按照上面的原理来说,virtqueue 是一个介于客户机前端和 qemu 后端的一个结构,用于在这两端之间传递数据。这里建立的 struct virtqueue 是客户机前端对于队列的管理的数据结构,在客户机的 linux 内核中通过 kmalloc_array 进行分配。
而队列的实体需要通过函数 virtio_find_vqs 查找或者生成,所以这里我们还把 callback 函数指定为 virtblk_done。当 buffer 使用发生变化的时候,我们需要调用这个 callback 函数进行通知。
根据 virtio_config_ops 的定义,virtio_find_vqs 会调用 vp_modern_find_vqs。
在 vp_modern_find_vqs 中,vp_find_vqs 会调用 vp_find_vqs_intx。
在 vp_find_vqs_intx 中,我们通过 request_irq 注册一个中断处理函数 vp_interrupt,当设备的配置信息发生改变,会产生一个中断,当设备向队列中写入信息时,也会会产生一个中断,我们称为 vq 中断,中断处理函数需要调用相应的队列的回调函数。
然后,我们根据队列的数目,依次调用 vp_setup_vq,完成 virtqueue、vring 的分配和初始化。
在 vring_create_virtqueue 中,我们会调用 vring_alloc_queue,来创建队列所需要的内存空间,然后调用 vring_init 初始化结构 struct vring,来管理队列的内存空间,调用 __vring_new_virtqueue,来创建 struct vring_virtqueue。
这个结构的一开始,是 struct virtqueue,它也是 struct virtqueue 的一个扩展,紧接着后面就是 struct vring。
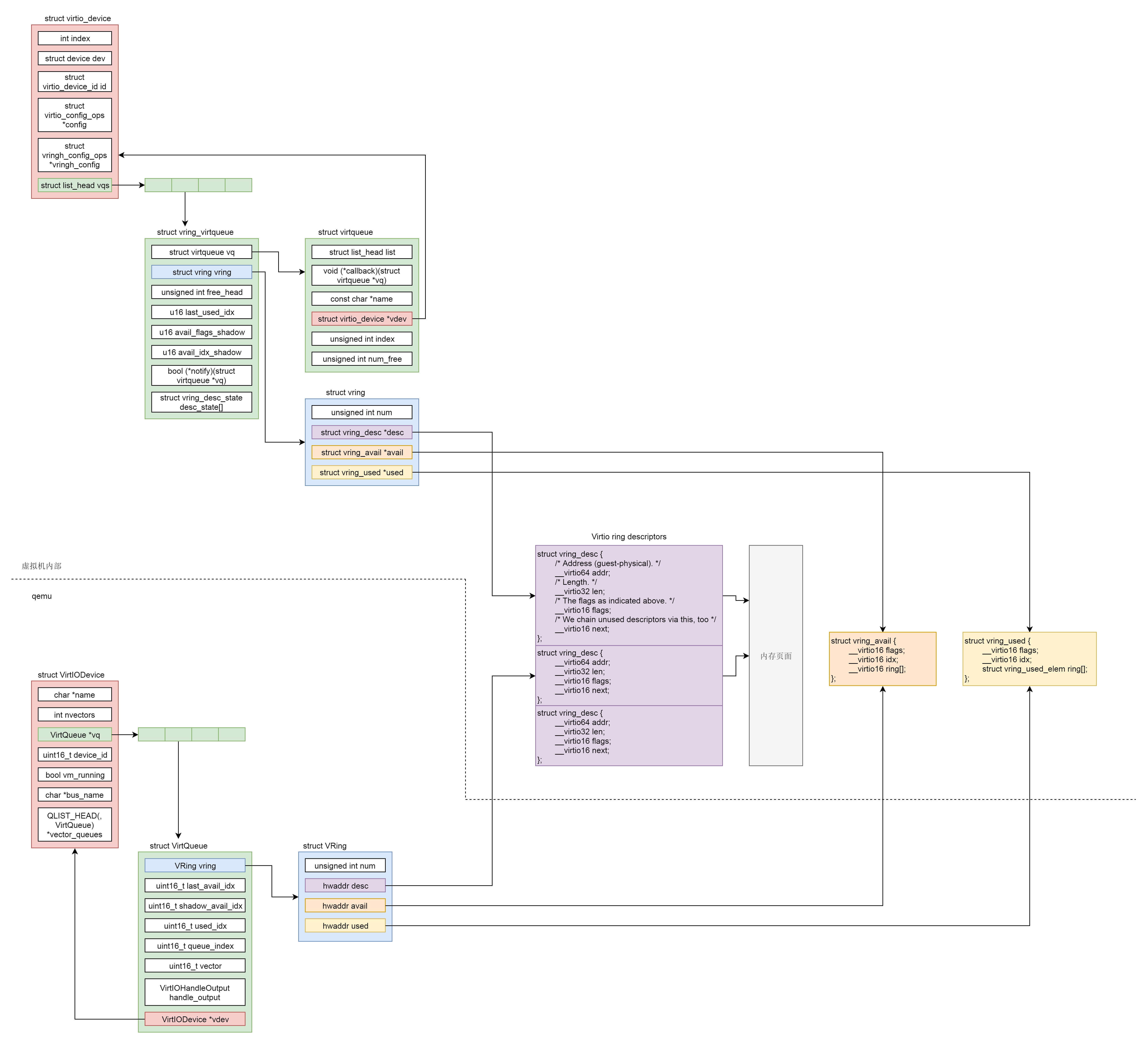
至此我们发现,虚拟机里面的 virtio 的前端是这样的结构:struct virtio_device 里面有一个 struct vring_virtqueue,在 struct vring_virtqueue 里面有一个 struct vring。
中间 virtio 队列的管理
还记不记得我们上面讲 qemu 初始化的时候,virtio 的后端有数据结构 VirtIODevice,VirtQueue 和 vring 一模一样,前端和后端对应起来,都应该指向刚才创建的那一段内存。
现在的问题是,我们刚才分配的内存在客户机的内核里面,如何告知 qemu 来访问这段内存呢?
别忘了,qemu 模拟出来的 virtio block device 只是一个 PCI 设备。对于客户机来讲,这是一个外部设备,我们可以通过给外部设备发送指令的方式告知外部设备,这就是代码中 vp_iowrite16 的作用。它会调用专门给外部设备发送指令的函数 iowrite,告诉外部的 PCI 设备。
告知的有三个地址 virtqueue_get_desc_addr、virtqueue_get_avail_addr,virtqueue_get_used_addr。从客户机角度来看,这里面的地址都是物理地址,也即 GPA(Guest Physical Address)。因为只有物理地址才是客户机和 qemu 程序都认可的地址,本来客户机的物理内存也是 qemu 模拟出来的。
在 qemu 中,对 PCI 总线添加一个设备的时候,我们会调用 virtio_pci_device_plugged。
在这里面,对于这个加载的设备进行 I/O 操作,会映射到读写某一块内存空间,对应的操作为 virtio_pci_config_ops,也即写入这块内存空间,这就相当于对于这个 PCI 设备进行某种配置。
对 PCI 设备进行配置的时候,会有这样的调用链:virtio_pci_config_write->virtio_ioport_write->virtio_queue_set_addr。设置 virtio 的 queue 的地址是一项很重要的操作。
从这里我们可以看出,qemu 后端的 VirtIODevice 的 VirtQueue 的 vring 的地址,被设置成了刚才给队列分配的内存的 GPA。
接着,我们来看一下这个队列的格式。
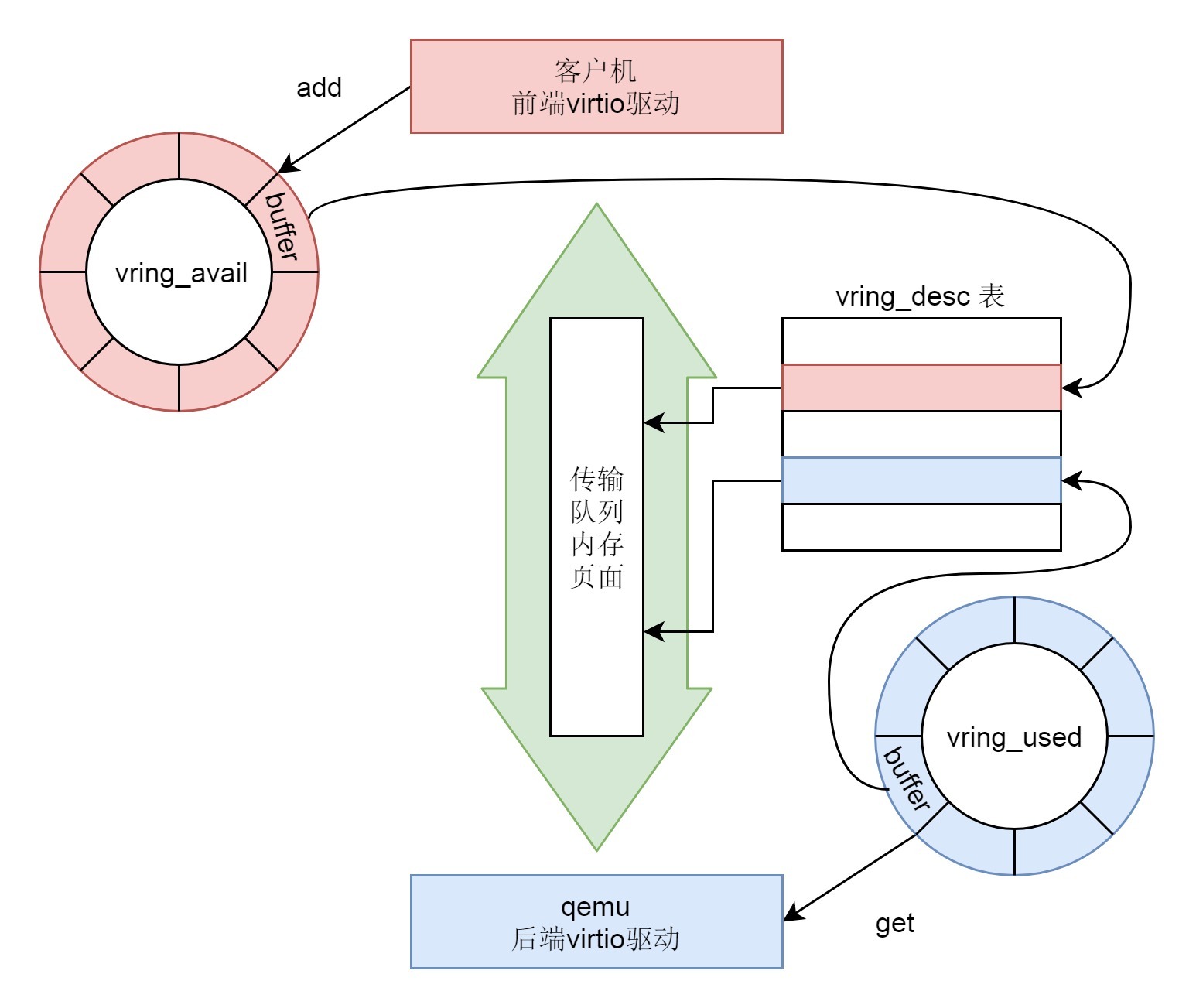
vring 包含三个成员:
- vring_desc 指向分配的内存块,用于存放客户机和 qemu 之间传输的数据。
- avail->ring[] 是发送端维护的环形队列,指向需要接收端处理的 vring_desc。
- used->ring[] 是接收端维护的环形队列,指向自己已经处理过了的 vring_desc。
数据写入的流程
接下来,我们来看,真的写入一个数据的时候,会发生什么。
按照上面 virtio 驱动初始化的时候的逻辑,blk_mq_make_request 会被调用。这个函数比较复杂,会分成多个分支,但是最终都会调用到 request_queue 的 virtio_mq_ops 的 queue_rq 函数。
根据 virtio_mq_ops 的定义,我们现在要调用 virtio_queue_rq。
在 virtio_queue_rq 中,我们会将请求写入的数据,通过 virtblk_add_req 放入 struct virtqueue。
因此,接下来的调用链为:virtblk_add_req->virtqueue_add_sgs->virtqueue_add。
在 virtqueue_add 函数中,我们能看到,free_head 指向的整个内存块空闲链表的起始位置,用 head 变量记住这个起始位置。
接下来,i 也指向这个起始位置,然后是一个 for 循环,将数据放到内存块里面,放的过程中,next 不断指向下一个空闲位置,这样空闲的内存块被不断的占用。等所有的写入都结束了,i 就会指向这次存放的内存块的下一个空闲位置,然后 free_head 就指向 i,因为前面的都填满了。
至此,从 head 到 i 之间的内存块,就是这次写入的全部数据。
于是,在 vring 的 avail 变量中,在 ring[] 数组中分配新的一项,在 avail 的位置,avail 的计算是 avail_idx_shadow & (vq->vring.num - 1),其中,avail_idx_shadow 是上一次的 avail 的位置。这里如果超过了 ring[] 数组的下标,则重新跳到起始位置,就说明是一个环。这次分配的新的 avail 的位置就存放新写入的从 head 到 i 之间的内存块。然后是 avail_idx_shadow++,这说明这一块内存可以被接收方读取了。
接下来,我们回到 virtio_queue_rq,调用 virtqueue_notify 通知接收方。而 virtqueue_notify 会调用 vp_notify。
然后,我们写入一个 I/O 会触发 VM exit。我们在解析 CPU 的时候看到过这个逻辑。
这次写入的也是一个 I/O 的内存空间,同样会触发 virtio_ioport_write,这次会调用 virtio_queue_notify。
virtio_queue_notify 会调用 VirtQueue 的 handle_output 函数,前面我们已经设置过这个函数了,是 virtio_blk_handle_output。
接下来的调用链为:virtio_blk_handle_output->virtio_blk_handle_output_do->virtio_blk_handle_vq。
在 virtio_blk_handle_vq 中,有一个 while 循环,在循环中调用函数 virtio_blk_get_request 从 vq 中取出请求,然后调用 virtio_blk_handle_request 处理从 vq 中取出的请求。
我们先来看 virtio_blk_get_request。
我们可以看到,virtio_blk_get_request 会调用 virtqueue_pop。在这里面,我们能看到对于 vring 的操作,也即从这里面将客户机里面写入的数据读取出来,放到 VirtIOBlockReq 结构中。
接下来,我们就要调用 virtio_blk_handle_request 处理这些数据。所以接下来的调用链为:virtio_blk_handle_request->virtio_blk_submit_multireq->submit_requests。
在 submit_requests 中,我们看到了 BlockBackend。这是在 qemu 启动的时候,打开 qcow2 文件的时候生成的,现在我们可以用它来写入文件了,调用的是 blk_aio_pwritev。
在 blk_aio_pwritev 中,我们看到,又是创建了一个协程来进行写入。写入完毕之后调用 virtio_blk_rw_complete->virtio_blk_req_complete。
在 virtio_blk_req_complete 中,我们先是调用 virtqueue_push,更新 vring 中 used 变量,表示这部分已经写入完毕,空间可以回收利用了。但是,这部分的改变仅仅改变了 qemu 后端的 vring,我们还需要通知客户机中 virtio 前端的 vring 的值,因而要调用 virtio_notify。virtio_notify 会调用 virtio_irq 发送一个中断。
还记得咱们前面注册过一个中断处理函数 vp_interrupt 吗?它就是干这个事情的。
就像前面说的一样 vp_interrupt 这个中断处理函数,一是处理配置变化,二是处理 I/O 结束。第二种的调用链为:vp_interrupt->vp_vring_interrupt->vring_interrupt。
在 vring_interrupt 中,我们会调用 callback 函数,这个也是在前面注册过的,是 virtblk_done。
接下来的调用链为:virtblk_done->virtqueue_get_buf->virtqueue_get_buf_ctx。
在 virtqueue_get_buf_ctx 中,我们可以看到,virtio 前端的 vring 中的 last_used_idx 加一,说明这块数据 qemu 后端已经消费完毕。我们可以通过 detach_buf 将其放入空闲队列中,留给以后的写入请求使用。
至此,整个存储虚拟化的写入流程才全部完成。
总结时刻
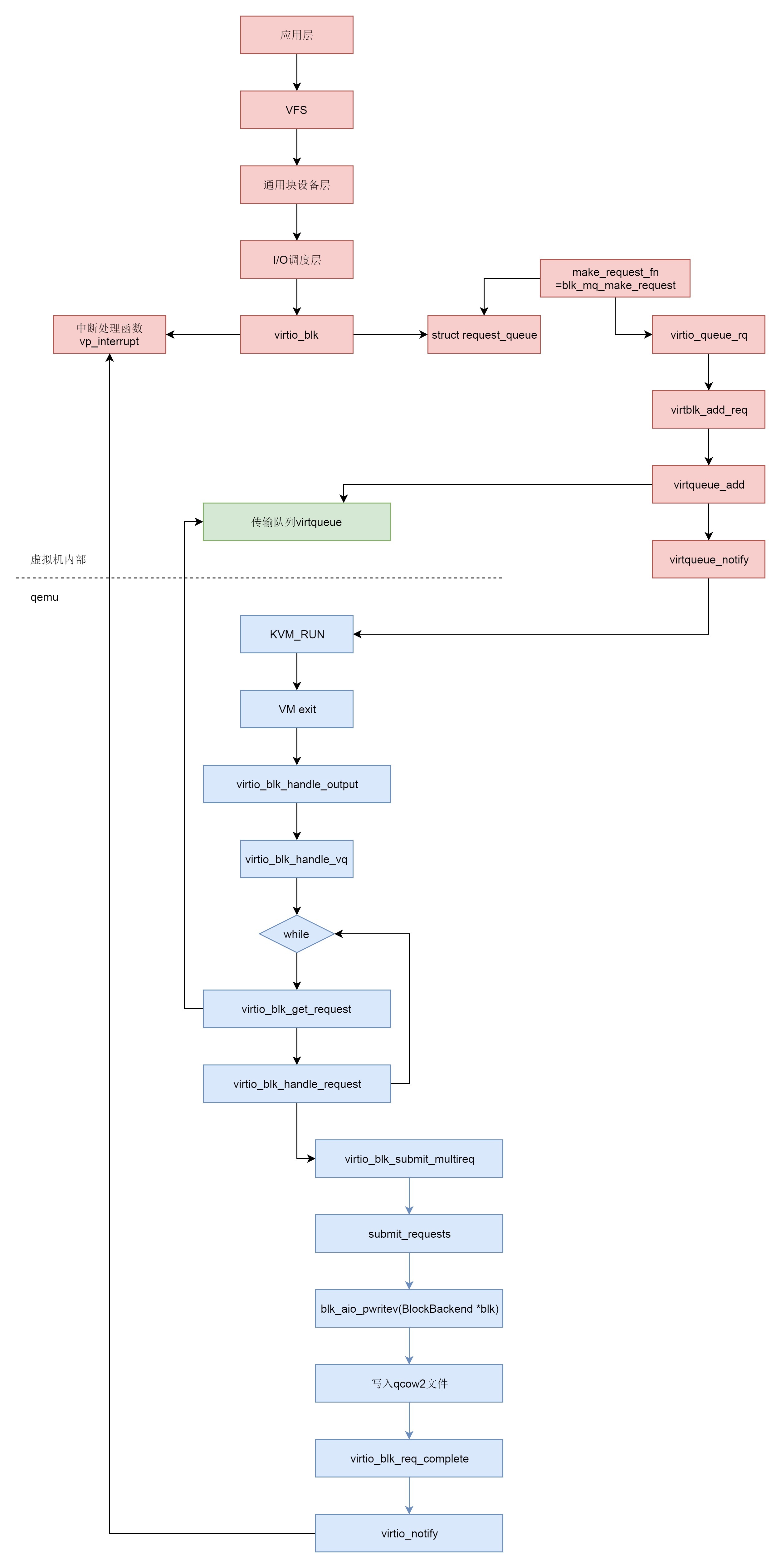
下面我们来总结一下存储虚拟化的场景下,整个写入的过程。
- 在虚拟机里面,应用层调用 write 系统调用写入文件。
- write 系统调用进入虚拟机里面的内核,经过 VFS,通用块设备层,I/O 调度层,到达块设备驱动。
- 虚拟机里面的块设备驱动是 virtio_blk,它和通用的块设备驱动一样,有一个 request queue,另外有一个函数 make_request_fn 会被设置为 blk_mq_make_request,这个函数用于将请求放入队列。
- 虚拟机里面的块设备驱动是 virtio_blk 会注册一个中断处理函数 vp_interrupt。当 qemu 写入完成之后,它会通知虚拟机里面的块设备驱动。
- blk_mq_make_request 最终调用 virtqueue_add,将请求添加到传输队列 virtqueue 中,然后调用 virtqueue_notify 通知 qemu。
- 在 qemu 中,本来虚拟机正处于 KVM_RUN 的状态,也即处于客户机状态。
- qemu 收到通知后,通过 VM exit 指令退出客户机状态,进入宿主机状态,根据退出原因,得知有 I/O 需要处理。
- qemu 调用 virtio_blk_handle_output,最终调用 virtio_blk_handle_vq。
- virtio_blk_handle_vq 里面有一个循环,在循环中,virtio_blk_get_request 函数从传输队列中拿出请求,然后调用 virtio_blk_handle_request 处理请求。
- virtio_blk_handle_request 会调用 blk_aio_pwritev,通过 BlockBackend 驱动写入 qcow2 文件。
- 写入完毕之后,virtio_blk_req_complete 会调用 virtio_notify 通知虚拟机里面的驱动。数据写入完成,刚才注册的中断处理函数 vp_interrupt 会收到这个通知。
课堂练习
请你沿着代码,仔细分析并牢记 virtqueue 的结构以及写入和读取方式。这个结构在下面的网络传输过程中,还要起大作用。
欢迎留言和我分享你的疑惑和见解,也欢迎收藏本节内容,反复研读。你也可以把今天的内容分享给你的朋友,和他一起学习和进步。

1716143665 拼课微信(1)
 没心没肺2019-07-31每次看到文中说还记得什么什么吗,我心里总是默默回答:不 记 得😂 1 2
没心没肺2019-07-31每次看到文中说还记得什么什么吗,我心里总是默默回答:不 记 得😂 1 2
